How pgtoken recovers GPU time by fixing what runs before it
Compute once. Store. Retrieve.

Your prompt has 100 tokens. 30 are your system prompt. They haven’t changed since you deployed. The other 70 are the user’s message - different every request.
Your inference server tokenizes all 100. Every request. Including the 30 it tokenized last time. And the time before that. And every request since the day you deployed.
This is the problem pgtoken solves.
What counts as the fixed part
The system prompt is the obvious case. But the fixed portion of a real prompt is almost always larger than just the system prompt.
Tool definitions. If you’re running a tool-calling model, your tool schemas are identical across every request for that deployment. A typical schema covering 10-15 tools runs 400-800 tokens. Every request tokenizes them from scratch.
Static RAG context. In a document-heavy RAG system, popular documents get retrieved repeatedly - different users, same queries, same chunks. Those chunks have token IDs. They were tokenized the last time that chunk appeared. The time before that. The time before that.
Conversation history. Prior turns in a session are settled. Turn 1’s token IDs were computed when turn 1 was processed. By turn 10, your model is re-tokenizing nine previous turns on every request. Those token IDs have not changed.
Few-shot examples. If you prepend the same examples to every request, they’re the same tokens every time.
In a real RAG deployment with a 200-token system prompt, 5,000 tokens of retrieved context, and a 50-token user query - the fixed portion could be 80-90% of the prompt. You’re spending most of your tokenization budget on tokens you’ve already computed.
Why it’s safe to skip
One paragraph, because this deserves to be stated precisely.
BPE tokenization is a deterministic function. It has no randomness, no state, no side effects. The merge table is fixed. The vocabulary is fixed. The same input text will always produce the same token IDs - not usually, not approximately, always. If the system prompt hasn’t changed, its token IDs are identical to the last request. And the one before that. The tokenizer is recomputing a result it already knows.
Store the result. Retrieve it instead of recomputing it.
What it costs today
Benchmark environment: Azure NC16as_T4_v3, 16 vCPU, T4 GPU. Qwen2.5-1.5B tokenizer. 140-token system prompt, identical across all requests. Input pipeline measured in isolation - tokenization only, no GPU, no forward pass. That isolation is intentional: the forward pass is the same for both pipelines. The only thing being measured is the CPU preprocessing step before the GPU sees anything.
Two pipelines:
Baseline: tokenizer.encode(system_prompt + query)
pgtoken: retrieve(system_prompt token_ids) + tokenizer.encode(query only)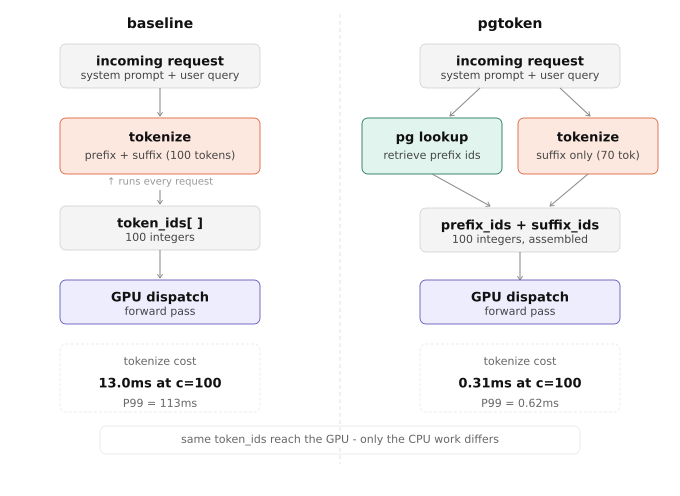
Results across concurrency levels:
Concurrency Tokenize: baseline → pgtoken Saving Throughput
──────────────────────────────────────────────────────────────────
1 0.32ms → 0.06ms 83% 10.9×
8 0.44ms → 0.11ms 74% 3.7×
100 13.0ms → 0.31ms 97.5% -The saving grows under load because the baseline degrades with contention while the pgtoken lookup does not. At concurrency=100, the baseline is queueing 100 processes on 16 cores to tokenize the same prefix. pgtoken is reading a dict.
At concurrency=1, 83% of tokenization work is eliminated. The overhead - the pgtoken lookup - costs 0.003ms. The saving is 0.26ms. The overhead is 1.1% of the saving.
At concurrency=100, baseline tokenization degraded to 13ms mean and 113ms P99. One hundred processes competing for 16 CPU cores, each waiting to run BPE merges on the same 140 tokens it already computed. pgtoken at the same concurrency: 0.31ms mean, 0.62ms P99. The prefix lookup is a dict read. It does not queue behind other processes.
The P99 gap - 113ms vs 0.62ms - is the number that matters. In a production system, P99 latency is what users feel during traffic spikes. 113ms before the GPU even sees the request, just for tokenizing a system prompt.
The GPU connection
CPU tokenization is the step before GPU dispatch. The GPU cannot start its forward pass until the tokenizer finishes. Every millisecond spent re-tokenizing the system prompt is a millisecond the GPU sits idle.
On a single T4 with sequential requests, cutting tokenization from 13ms to 0.31ms means the GPU receives its next batch 12.7ms sooner per request. Across 1,000,000 requests, the total GPU idle time eliminated adds up to about 3.5 GPU-hours of recovered capacity.
The GPU does not get faster. It gets less idle. The throughput gain comes from removing the bottleneck before it, not from optimising the GPU itself. This is the often-missed leverage point in inference pipelines: the CPU preprocessing step that nobody profiles because it looks fast in isolation.
How pgtoken implements this
At application startup, before any user request arrives, you tokenize the static prefix once and store it:
python
prefix_ids = tokenizer.encode(system_prompt)
store.store(system_prompt, prefix_ids)On every subsequent request, retrieve instead of recompute:
python
prefix_ids = store.lookup(system_prompt) # 0.003ms - dict read
suffix_ids = tokenizer.encode(user_query) # tokenize only the variable part
token_ids = prefix_ids + suffix_ids # join in integer space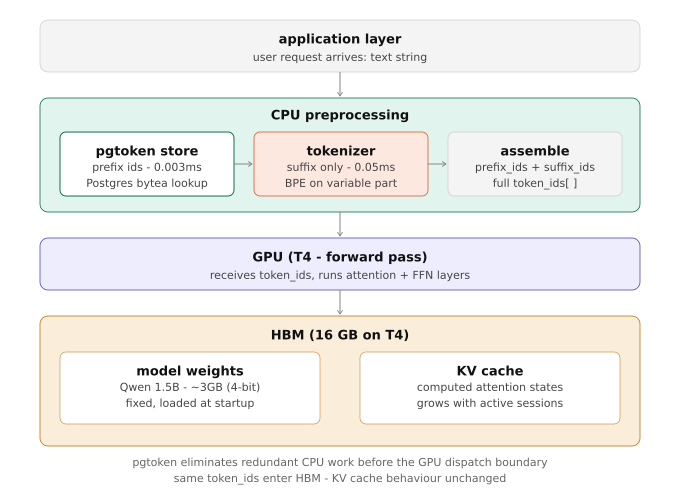
The stored representation is rank-varint encoded bytea in Postgres - ~1.7 bytes per token on average versus 4 bytes for raw int32. The codebook ranks tokens by frequency so common tokens encode to 1 byte. The 4-byte header enables O(1) token counting without decoding.
The tokenizer ran once. Every request after that is a retrieval.
For the full technical implementation - the varint encoding, the codebook design, the C extension internals - see the [pgtoken technical article].
What this doesn’t cover
This benchmark measures explicit prefix caching - you declare the boundary between fixed and variable. The static prefix is known in advance, stored at startup, retrieved on every request.
The natural next question: what if the boundary isn’t known in advance? What if you want the system to discover it?
Two mechanisms make implicit detection possible. A sliding window approach watches recent requests, finds the longest common prefix across them, and promotes any sequence that appears frequently enough to a stored entry automatically. A radix tree approach inserts every incoming token sequence into a prefix tree - shared prefixes emerge structurally wherever the tree branches, without any boundary declaration. Both approaches use pgtoken as the storage layer underneath: the detection mechanism finds the prefix, pgtoken stores it, every subsequent request retrieves it.
Explicit caching - what this article benchmarks - handles the cases you already know about: your system prompt, your tool schemas, your static context. Implicit detection handles the cases you don’t. The storage primitive is the same either way.